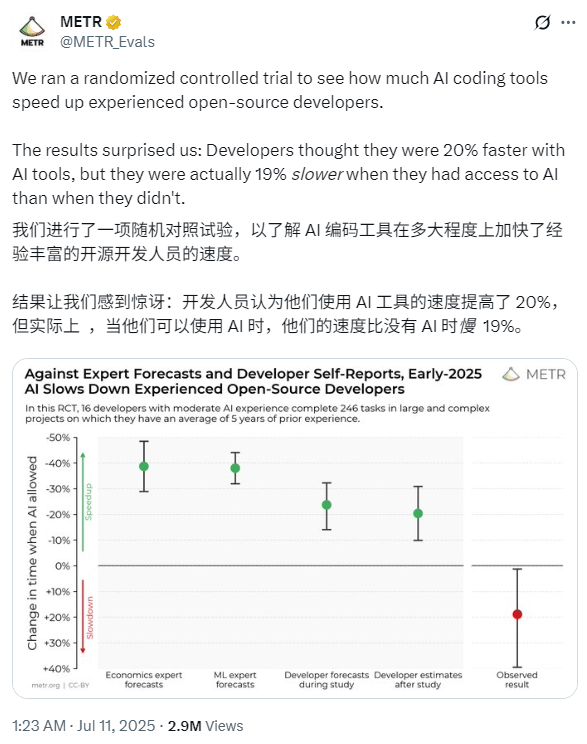
 随着大型模型的兴起,AI编程领域正在发生土壤颤抖的变化。已经出现了各种编程模型和编程工具,通过实用功能(例如自动代码完成和自动举止)为开发商的日至日工作提供了极大的便利,并在一定程度上提高了开发效率。但是,问题是,这是AI编程工具的影响吗?最近,一个非营利性的AI研究组织“ METR”进行了一个随机对照实验,以了解AI编程工具如何加速经验丰富的开发人员的工作效率。结果令人惊讶:开发人员最初认为,使用工具后的速度可以提高20%,但实际上,速度比不使用AI工具的速度要慢19%。这个结论在社交媒体X上爆炸了,大约300万观看次数。如下图所示:与专家开发人员的专家和IN相反学费,AI编程工具在2025年初将减缓经验丰富的开发人员的开发。在这个随机对照实验中,有16位具有适度AI编程经验的开发人员完成了246个大型复杂项目,他们平均拥有5年的开发经验。网民对这项调查的反应不同。有些人是同情和冒险的。有些人询问度量测量值,该指标说“完成任务”的时间不能等于“生产力”,而Medium ExperienceAi是一个同样糟糕的设置,并进行了复杂的项目测试。 “我们应该调查普通人(不变)使用AI编写软件的速度,”有些人还说。在编码/代理基准测试时的研究动机已被证明可以帮助了解AI的能力,他们经常为规模和效率牺牲真实性 - 这些活动具有自己的作用,不需要了解以前的环境,并且不需要使用算法进行评估,并且不需要评估获得许多重要的功能。这些功能可能会导致基准克服AI功能。另一方面,由于基准进行实时而没有实时联系的基准运行,但该模型仍无法完成任务,例如开发出色,例如iJust小瓶颈,人们可以在实际情况下很容易修复。通常,很难将基准标记直接转换为现实世界效果。梅尔(Metr)表示,评估AI对软件开发人员生产率的影响可能会为基准测试提供进一步的证据,并有助于了解AI对AI R&D加速度的总体影响。 METR鼓励了来自大型开放资源存储库(平均22k+Stars和100万行代码)的16位经验丰富的开发人员,并贡献了很多年,从而直接衡量了现实AI工具对软件开发的影响,并直接衡量了现实AI工具对软件开发的影响,并贡献了很多年。这些开发人员提供了他们认为在仓库中很重要的真实问题清单使用(总计246) - 即通常属于他们的日子活动,组织,开发和重构活动的错误。接下来,METR随机分配了每个问题,允许或禁止开发人员在与之交谈时使用AI。当允许AI时,开发人员可以选择他们喜欢的任何工具(Cursor Pro在研究过程中主要用于Claude 3.5/3.7十四行诗)。禁止时,它们在没有生成的AI帮助的情况下工作。开发人员在完成任务完成时记录屏幕(平均每次大约需要两个小时),并报告完成所需的全职。当然,Metr向开发人员支付以每小时150美元的标准(大约1,080元人满1,080元)的标准进行研究。结果表明,当允许开发人员使用AI工具时,他们需要将赞美问题解决19%的时间 - 效率的重大崩溃,与专家预测和开发人员的理解相反。理解与真理之间的差距是令人惊讶的是:开发人员希望AI将其加速24%,即使在卓越表现之后,他们仍然认为AI会将其加速20%。以下显示了开发人员预测的平均时间和实际执行时间。我们可以清楚地看到,当允许开发人员使用AI工具时,它们的使用寿命更长。当允许AI时,开发人员花费的时间更少,找到信息,而不是花更多的时间写单词,等待或审查AI输出并闲置。梅尔发现,放缓发展不是单一原因的一种,而是多种因素组合的原因。为了更好地理解这些因素,METR检查了实验环境中的20个功能,发现其中5个可能导致发育放缓,而8个表现出-A -a -a -a -a -a -a -a -a -a效果。在此过程中,Metr排除了许多实验中断,例如使用切割模型,这些破坏符合分配PO的处理许可并没有被选为放弃问题(例如,交出AI的不良活动以减少不使用AI组的平均难度),并在使用AI时提交了类似的质量PRS(被抓取的请求),而不是使用AI。结果表明,如果使用不同的结果指标,估计方法或执行不同的子集/数据下分析,则仍然存在降低开发速度。有关更详细的研究结果,请参阅原始论文:论文标题:衡量2025年初AI对经验丰富的开放源开发人员生产力论文的影响:https://metr.org/early_2025_ai_ai_ai_ai_ai_ai_ai_experienced_os_os_os_os_devs_devs_tang在两个重要的结论中,尤其是在某些重要的情况下,可能还没有提高某些重要的工具,并且可能会提高一定的工具,并且可能会提高生产工具。关于卓越的自我报告并不是可靠的,真正了解AI对生产率的影响,我们需要对真实环境的实验数据。但是,梅特还说他们预选根本不代表该软件工程(也许是大多数),而声明可以更有效地使用当前模型,并且未来模型可能会更好。当然,无法衡量完美 - 人们想要实现AI系统的任务是多样,复杂且难以研究的。不同技术之间存在重大的权衡,并且重要的是要继续开发和使用不同的评估方法,以更全面地描述AI的当前状态和方向。将来,元R希望进行类似的AI研究,以监测AI带来的加速度(或放缓)的趋势,并且这种评估方法可能比基准测试更难“播放”。博客地址:https://metr.org/blog/2025-07-10-early-2025-i--ipperienced-os-iv-ludy/
随着大型模型的兴起,AI编程领域正在发生土壤颤抖的变化。已经出现了各种编程模型和编程工具,通过实用功能(例如自动代码完成和自动举止)为开发商的日至日工作提供了极大的便利,并在一定程度上提高了开发效率。但是,问题是,这是AI编程工具的影响吗?最近,一个非营利性的AI研究组织“ METR”进行了一个随机对照实验,以了解AI编程工具如何加速经验丰富的开发人员的工作效率。结果令人惊讶:开发人员最初认为,使用工具后的速度可以提高20%,但实际上,速度比不使用AI工具的速度要慢19%。这个结论在社交媒体X上爆炸了,大约300万观看次数。如下图所示:与专家开发人员的专家和IN相反学费,AI编程工具在2025年初将减缓经验丰富的开发人员的开发。在这个随机对照实验中,有16位具有适度AI编程经验的开发人员完成了246个大型复杂项目,他们平均拥有5年的开发经验。网民对这项调查的反应不同。有些人是同情和冒险的。有些人询问度量测量值,该指标说“完成任务”的时间不能等于“生产力”,而Medium ExperienceAi是一个同样糟糕的设置,并进行了复杂的项目测试。 “我们应该调查普通人(不变)使用AI编写软件的速度,”有些人还说。在编码/代理基准测试时的研究动机已被证明可以帮助了解AI的能力,他们经常为规模和效率牺牲真实性 - 这些活动具有自己的作用,不需要了解以前的环境,并且不需要使用算法进行评估,并且不需要评估获得许多重要的功能。这些功能可能会导致基准克服AI功能。另一方面,由于基准进行实时而没有实时联系的基准运行,但该模型仍无法完成任务,例如开发出色,例如iJust小瓶颈,人们可以在实际情况下很容易修复。通常,很难将基准标记直接转换为现实世界效果。梅尔(Metr)表示,评估AI对软件开发人员生产率的影响可能会为基准测试提供进一步的证据,并有助于了解AI对AI R&D加速度的总体影响。 METR鼓励了来自大型开放资源存储库(平均22k+Stars和100万行代码)的16位经验丰富的开发人员,并贡献了很多年,从而直接衡量了现实AI工具对软件开发的影响,并直接衡量了现实AI工具对软件开发的影响,并贡献了很多年。这些开发人员提供了他们认为在仓库中很重要的真实问题清单使用(总计246) - 即通常属于他们的日子活动,组织,开发和重构活动的错误。接下来,METR随机分配了每个问题,允许或禁止开发人员在与之交谈时使用AI。当允许AI时,开发人员可以选择他们喜欢的任何工具(Cursor Pro在研究过程中主要用于Claude 3.5/3.7十四行诗)。禁止时,它们在没有生成的AI帮助的情况下工作。开发人员在完成任务完成时记录屏幕(平均每次大约需要两个小时),并报告完成所需的全职。当然,Metr向开发人员支付以每小时150美元的标准(大约1,080元人满1,080元)的标准进行研究。结果表明,当允许开发人员使用AI工具时,他们需要将赞美问题解决19%的时间 - 效率的重大崩溃,与专家预测和开发人员的理解相反。理解与真理之间的差距是令人惊讶的是:开发人员希望AI将其加速24%,即使在卓越表现之后,他们仍然认为AI会将其加速20%。以下显示了开发人员预测的平均时间和实际执行时间。我们可以清楚地看到,当允许开发人员使用AI工具时,它们的使用寿命更长。当允许AI时,开发人员花费的时间更少,找到信息,而不是花更多的时间写单词,等待或审查AI输出并闲置。梅尔发现,放缓发展不是单一原因的一种,而是多种因素组合的原因。为了更好地理解这些因素,METR检查了实验环境中的20个功能,发现其中5个可能导致发育放缓,而8个表现出-A -a -a -a -a -a -a -a -a -a效果。在此过程中,Metr排除了许多实验中断,例如使用切割模型,这些破坏符合分配PO的处理许可并没有被选为放弃问题(例如,交出AI的不良活动以减少不使用AI组的平均难度),并在使用AI时提交了类似的质量PRS(被抓取的请求),而不是使用AI。结果表明,如果使用不同的结果指标,估计方法或执行不同的子集/数据下分析,则仍然存在降低开发速度。有关更详细的研究结果,请参阅原始论文:论文标题:衡量2025年初AI对经验丰富的开放源开发人员生产力论文的影响:https://metr.org/early_2025_ai_ai_ai_ai_ai_ai_ai_experienced_os_os_os_os_devs_devs_tang在两个重要的结论中,尤其是在某些重要的情况下,可能还没有提高某些重要的工具,并且可能会提高一定的工具,并且可能会提高生产工具。关于卓越的自我报告并不是可靠的,真正了解AI对生产率的影响,我们需要对真实环境的实验数据。但是,梅特还说他们预选根本不代表该软件工程(也许是大多数),而声明可以更有效地使用当前模型,并且未来模型可能会更好。当然,无法衡量完美 - 人们想要实现AI系统的任务是多样,复杂且难以研究的。不同技术之间存在重大的权衡,并且重要的是要继续开发和使用不同的评估方法,以更全面地描述AI的当前状态和方向。将来,元R希望进行类似的AI研究,以监测AI带来的加速度(或放缓)的趋势,并且这种评估方法可能比基准测试更难“播放”。博客地址:https://metr.org/blog/2025-07-10-early-2025-i--ipperienced-os-iv-ludy/